
토큰화란? 형태소 분석이란?
자연어처리 과정 중에는 토큰화(Tokenize) 과정이 있다.
한국어 토큰화를 진행할 때에는 형태소(morpheme)란 기준으로 토큰화 하기 때문에 '형태소 분석'이라고도 불린다.
한국어 토크나이저 및 형태소 분석기는 Mecab, Okt, Komoran, Kkma, Hannanum 등 여러가지가 있다.
그 중 오늘은 Mecab을 사용해서 토큰화 및 형태소분석을 해보려고 한다.
Mecab
Mecab은 원래 일본어 형태소 분석기로 개발되었다. 일본어와 문법 체계가 비슷한 한국어를 위해 '은전한닢'이라는 한국어로 포팅하는 프로젝트를 통해 한국어 자연어 처리에 크게 기여한 형태소 분석기라고 한다.
위에서 말한 여러 형태소 분석기들이 있지만, 일반적으로 그 중 가장 뛰어난 성능을 보인다고 알려져있다.
하지만 다른 형태소 분석기들에 비해 비교적 설치와 세팅이 번거롭다고 한다!
Mecab, Okt, Komoran, Kkma, Hannanum 모두 KoNLPy라는 패키지를 통해 제공하지만, Windows 환경에서는 Mecab을 공식적으로 제공하지 않는다.
Mecab for Windows, 윈도우에서 Mecab 사용하기
(1). KoNLPy 설치
Mecab을 설치하기 전에, 기본적으로 KoNLPy가 설치되어 있어야 한다.
- 내 시스템에 설치된 파이썬의 “비트 수”가 OS의 비트 수와 일치하는지 확인해주세요. 예를 들어, 64비트 윈도우를 사용하고 있다면 64비트 파이썬이, 32비트 윈도우를 사용하고 있다면 32비트 파이썬이 설치되어 있어야 합니다. 비트 수가 서로 일치하지 않는다면 OS에 맞게 파이썬을 재설치합니다.
- 윈도우 비트 수 확인하는 법
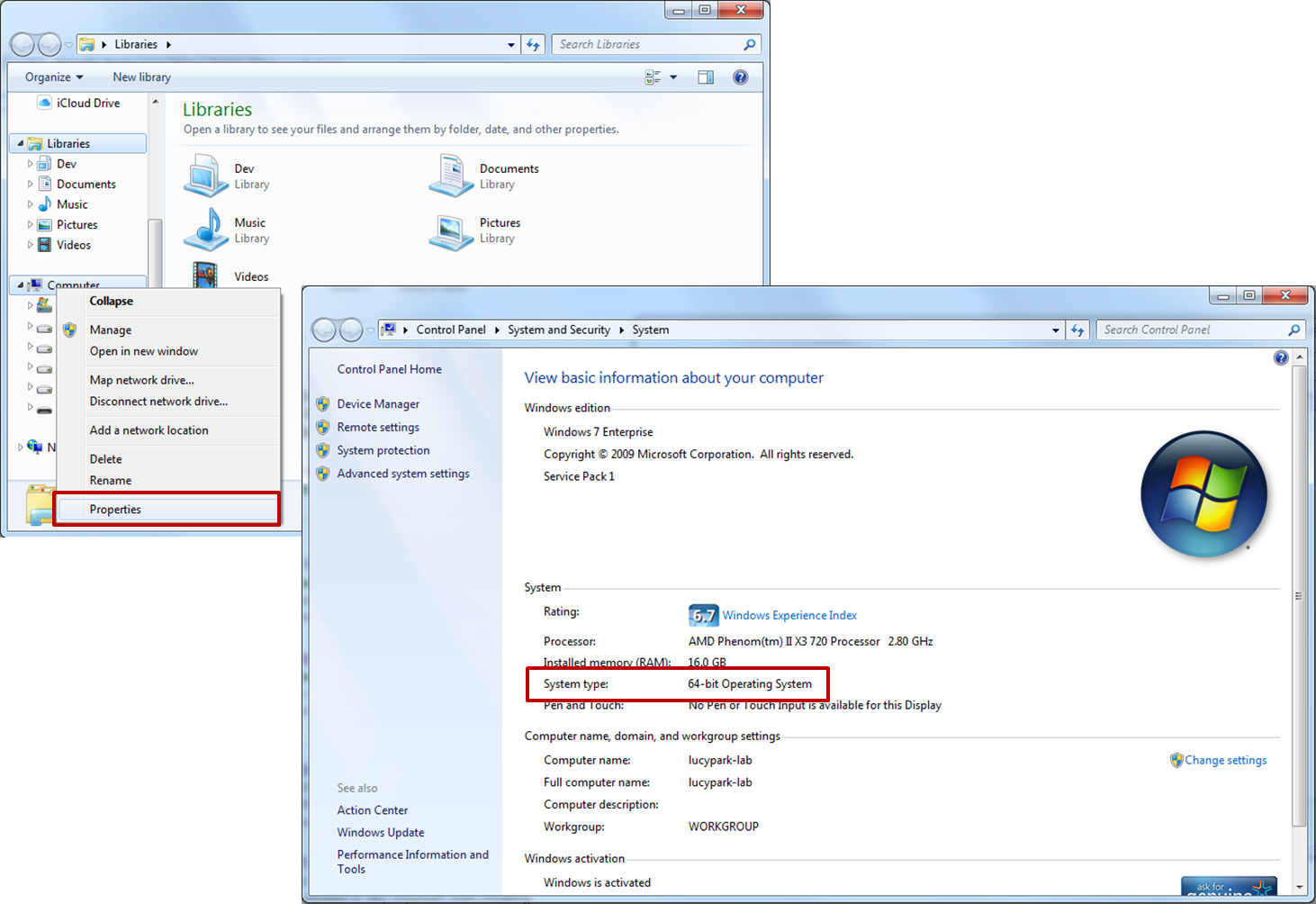
-
- 파이썬 비트 수 확인하는 법
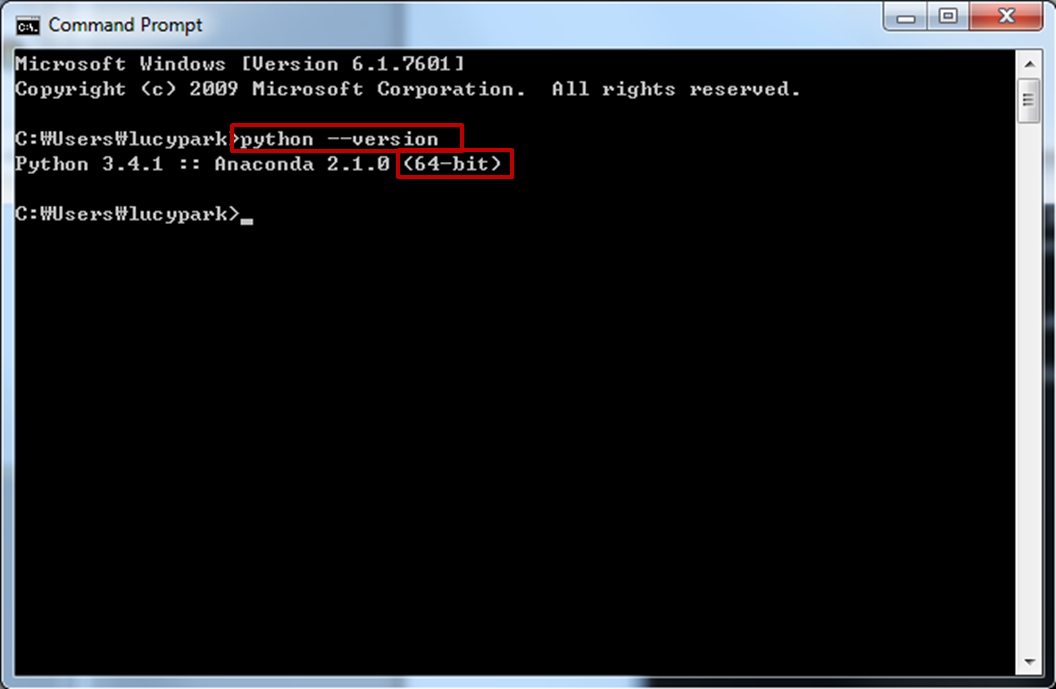
- OS와 비트 수가 일치하고, 버젼이 1.7 이상인 자바가 설치되어 있나요? 만일 그렇지 않다면 JDK를 설치합니다. 자바와 OS의 비트 수가 꼭 일치하도록 해주세요.
- JAVA_HOME을 설정합니다.
- OS의 비트 수와 일치하는 JPype1 (>=0.5.7)를 설치해주세요. 32비트 OS에는 win32, 64비트 OS에는 win-amd64 파일을 사용하면 됩니다. whl 파일로 설치하는 경우에는 다음과 같이 명령프롬프트에서 pip을 업그레이드해주세요. (명령프롬프트는 Windows + r을 누른 후 실행창에서 cmd를 입력하면 띄울 수 있습니다.)
pip install --upgrade pip
pip install JPype1-0.5.7-cp27-none-win_amd64.whl
- 마지막으로, 명령프롬프트에서 KoNLPy를 설치합니다.
pip install konlpy
(2) C:\mecab 생성

Mecab 설치 전에, Mecab을 설치할 폴더를 C드라이브 바로 아래에 만들어준다.
(3) mecab-ko-msvc 설치

- Pysnow/mecab-ko-msbc 에 접속해서 각자 환경에 맞는 .zip파일을 다운로드한다.
- 압축파일을 이전에 만든 'C:\mecab' 폴더에 풀어준다.(4) mecab-ko-dic-msvc 설치
(4) mecab-ko-dic-msvc 설치

1. Pysnow/mecab-ko-dic-mvsc에접속해서 한국어 단어 사전인 'mecab-ko-dic-msvc.zip'파일을 다운로드한다.
2. 똑같이 압축파일을 C:\mecab'에 풀어준다.
(5). python wheel 설치

python에서 mecab-ko-msvc를 빌드할 수 있도록 해주는 mecab-python-msvc를 설치해주어야 한다.
- Pysnow/mecab-python-msvc 에 접속해서 각자 python버전, window버전에 맞는 파일을 다운로드 한다. (python=3.9 -> cp39)
최종 환경
최종적으로 'C:\mecab'에 아래 폴더와 같이 구성되어야 한다.

Mecab 사용
from knlpy.tag imnport Medcab
mecab = Meacb(dicpath='C:/mecab/mecab-ko-dic)
mecab.morphs("아버지가방에들어가신다.")
나는 언론사들의 정치 기사를 수집하고, Mecab을 이용해 언론사별 정치 편향성 분석을 하려고 하였다.
하지만 Mecab은 '더불어민주당', '국민의힘'과 같은 정당의 이름을 다음과 같이 토큰화 하였다.
더불어민주당 -> 더불어, 민주, 당
국민의힘 -> 국민, 의 , 힘
결론: 사용자 사전 추가가 필요하다!
Mecab 사용자 사전 추가
(1). user-dic에 추가하고 싶은 단어 추가

- 명사 추가:
user-dic/nnp.csv - 사람 이름 추가:
user-dic/person.csv - 장소 이름 추가:
user-dic/place.csv - 일반적인 고유명사 추가
대우,,,,NNP,\*,F,대우,\*, \* , \* ,\*
- 인명 추가
까비,,,,NNP,인명,F,까비,_,_,_,_
- 지명 추가
구글,,,,NNP,*,T,구글,*,*,*,*세종,,,,NNP,지명,T,세종,_,_,_,_세종시,,,,NNP,지명,F,세종시,Compound,_,_,세종/NNP/지명+시/NNG/\*
처음에 .csv파일을 직접 열어서 수정했지만, 그렇게 수정하게 되면 파일 손상으로 인해 이후에 컴파일이 제대로 되지 않는 것으로 추정된다. 그렇기 때문에 python code를 통해 user-dic을 추가해보자.
user-dic 확인
# user-dic 확인
def checkUserDic():
with open("C:/mecab/user-dic/nnp.csv", 'r', encoding='utf-8') as f:
file_data = f.readlines()
print(file_data)
checkUserDic()종성 유무 확인
# 종성 유무 확인
def has_coda(word):
return (ord(word[-1]) - 44032) % 28 > 0
print(has_coda("word"))user-dic에 단어 추가
# user-dic에 단어 추가
def addUserDic(word: str, has_coda: bool):
path = "C:/mecab/user-dic/nnp.csv"
if has_coda:
has_coda = 'T'
else:
has_coda = 'F'
with open(path, 'r', encoding='utf-8') as f:
file_data = f.readlines()
file_data.append(f'{word},,,,NNP,*,{has_coda},{word},*,*,*,*,*\n')
with open(path, 'w', encoding='utf-8') as f:
for line in file_data:
f.write(line)
print(f"단어 '{word}'(이)가 {path}에 추가되었습니다.")
(2). Compile

- Jupyter 사용중이라면, 종료
- powershell (관리자 모드) 실행
- C:\mecab'으로 이동,
\`\`cd C"\\mecab .\\tools\\add-userdic-win.ps1
사용자 사전에 추가되었는지 확인 (C:/mecab/mecab-ko-dic/user-nnp.csv)
# user-nnp.csv 확인 (사용자 사전에 추가 되었는지)
def checkAddedUserDic():
with open("C:/mecab/mecab-ko-dic/user-nnp.csv", 'r', encoding='utf-8') as f:
file_data = f.readlines()
print(file_data)
checkAddedUserDic()
(3). 단어 사전 우선순위 변경
사용자 사전에 단어를 추가하더라도, 형태소 분석을 실시했을 때, 사전 추가 이전이랑 결과가 똑같이 나오는 경우가 있다. 이 땐, 해당 단어의 우선순위를 변경해주면 된다.
# 우선순위 변경
def changePriority(word: str, priority: int):
path = "C:/mecab/mecab-ko-dic/user-nnp.csv"
with open(path, 'r', encoding='utf-8') as f:
file_data = f.readlines()
for file in file_data:
if word in file:
idx = file_data.index(file)
file = file.split(',')
file[3] = str(priority)
file = ','.join(file)
break
file_data[idx] = file
with open(path, 'w', encoding='utf-8') as f:
for line in file_data:
f.write(line)
print(f"단어 '{word}'의 우선순위가 {priority}(으)로 변경되었습니다.")
checkAddedUserDic()
changePriority("word", 0)
(4). Compile

- Jupyter 사용중이라면, 종료
- powershell (관리자 모드) 실행
- C:\mecab'으로 이동,
\`\`cd C"\\mecab \`\` .\\tools\\compile-win.ps1
(5). 결과 확인

사용자 사전에 단어 추가, 우선 순위까지 변경 후 형태소 분석을 다시 실행보니 원하는대로 형태소 분석이 진행되는 것을 볼 수 있다.
'Data Science > NLP' 카테고리의 다른 글
| [NLP] 토크나이저(Tokenizer) 비교 Mecab, Okt, Komoran, Kannanum, Kkma (0) | 2024.06.05 |
|---|